Linear regression part two - finding the covariance of the quadratic loss minimizing line under homoskedasticity.
Last time, I began with a graph.
Namely, this one:
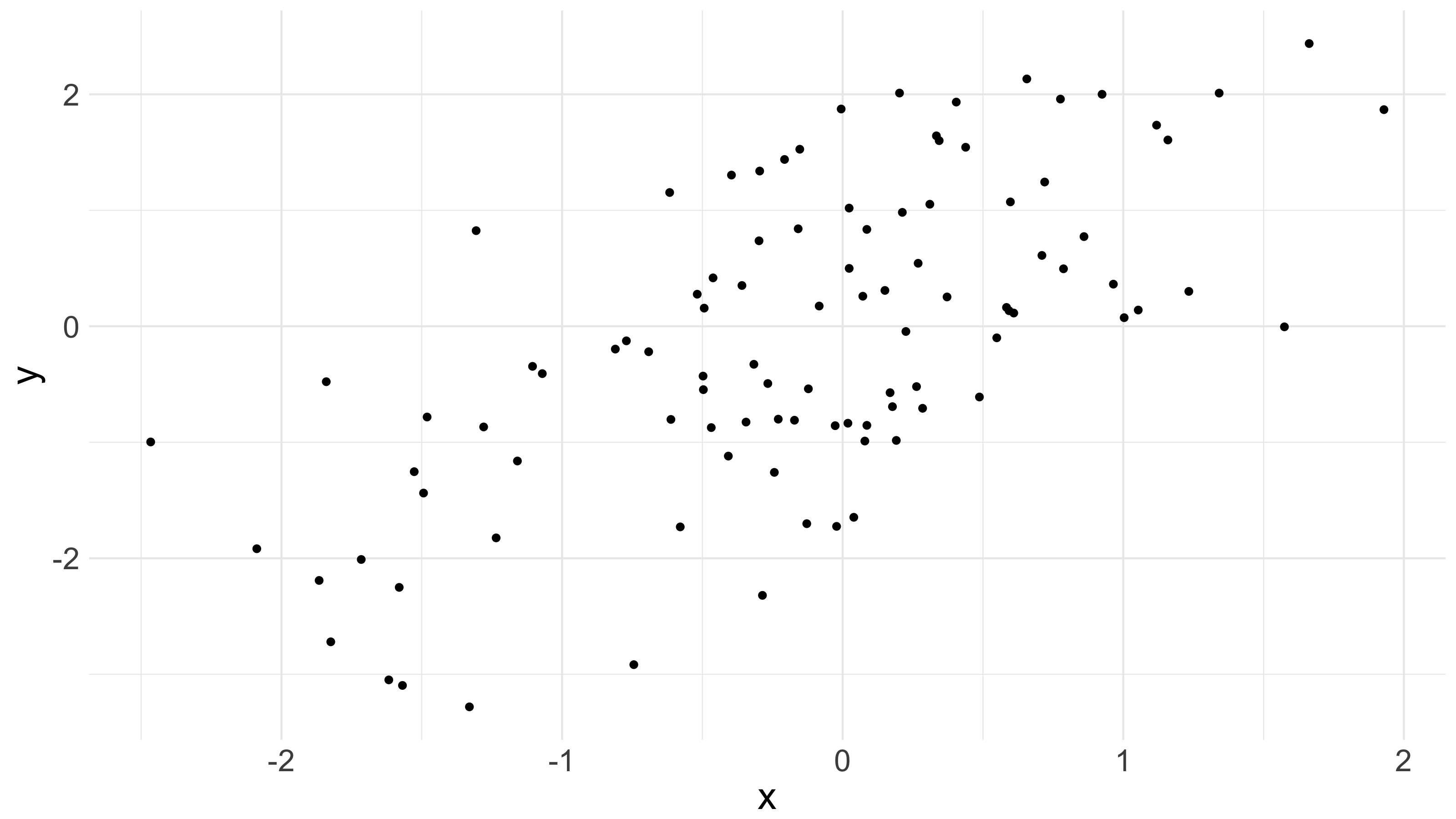
And we regarded the points on that graph as fixed, and found the linear function of which minimized quadratic loss for those points. Recall we assumed nothing stochastic; we were just minimizing a loss function taken over fixed data. And recall also that if we let
then we found that the vector
supplies the line which minimizes quadratic loss for our data. Its first element is the intercept, and its second is the slope.
But typically, we do not think of our data as fixed. Instead, we see each data point as a realization from a chance process – a realization from a joint probability distribution, , governing and . (We might, for example, think of as weight, and as height, and then imagine selecting someone at random. would then describe the probability of selecting a person of weight and height .)
And if we do see our data as realizations from a chance process, then we might wonder: if we had seen alternative realizations from , how would we expect our quadratic-loss-minimizing line to have differed? The below picture, for example, shows two 100 data point samples from the same underlying distribution on and , along with the quadratic-loss-minimizing lines for each:
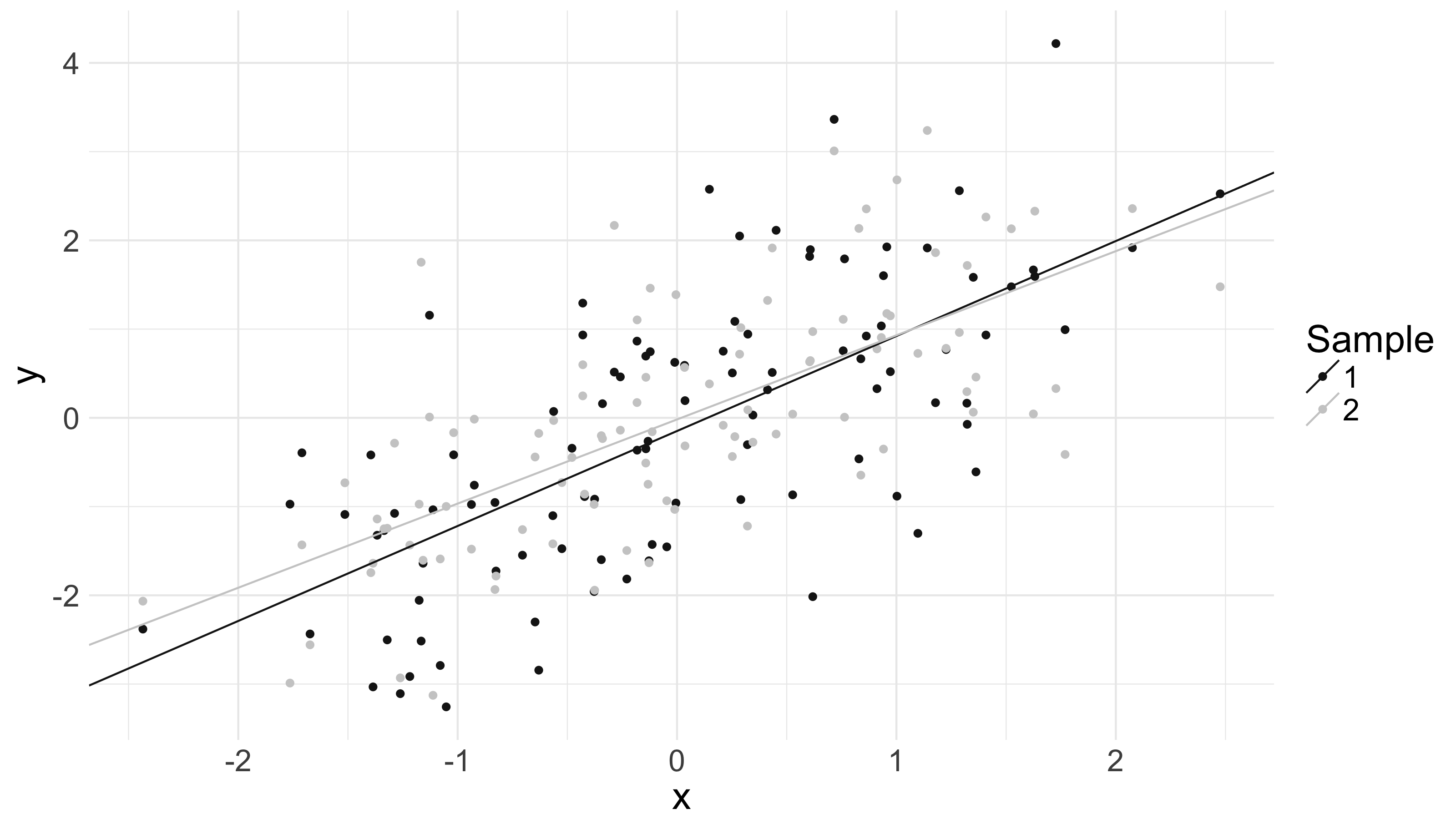
Appreciate how they shift and vary.
Now, we might also wonder: if we regard our -values as fixed, how would we expect our quadratic-loss-minimizing line to have varied? That is, how would we expect them to vary given alternative realizations from ?
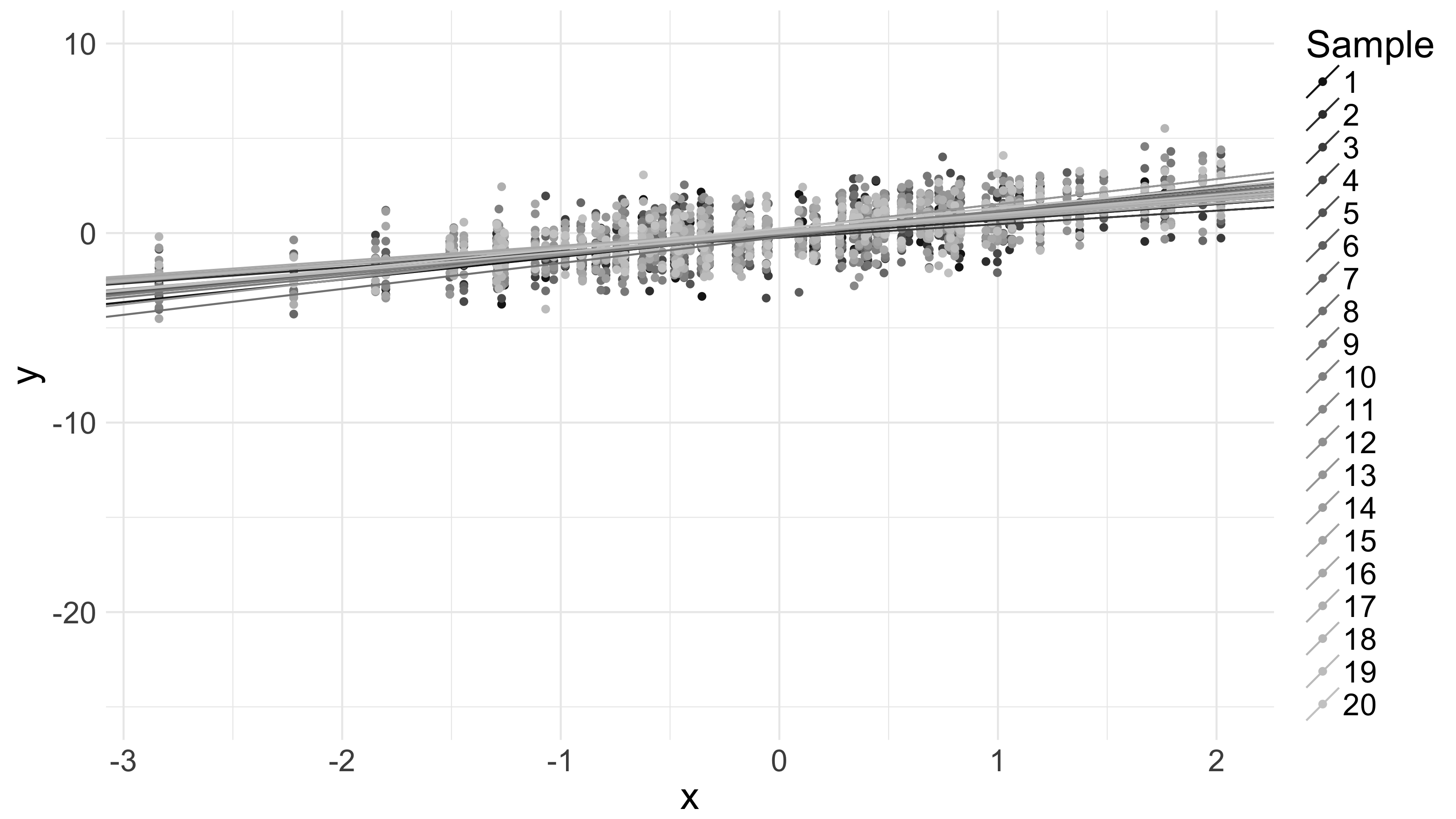
The below picture shows 20 100-data point samples from the same distribution , along with quadratic-loss-minimizing lines for each:
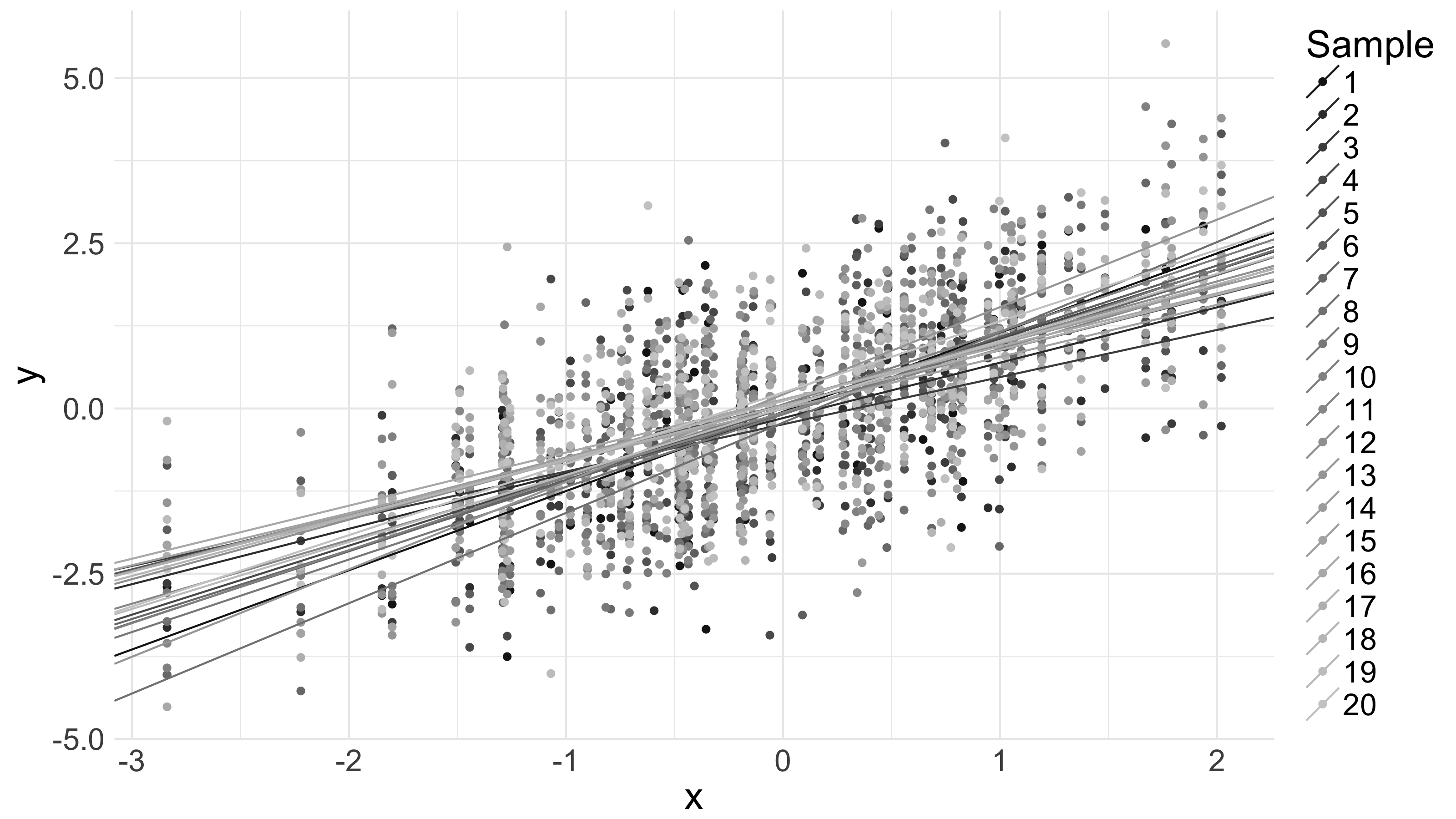
Appreciate, again, how they shift and vary. Notice also the vertical striations in the data on the graph. These are a result of the fact that the vector of -values is fixed, and I’ve sampled from around those fixed -values.
The difference between the first question – ‘how would I expect the lines to vary if I saw alternative realizations from ?’ – and the second question – ‘how would I expect the lines to vary if I saw alternative realizations from ?’ – is subtle. The first asks – across samples from , how do quadratic-loss-minimizers tend to vary. The second asks – across all samples from where the vector of values is equal to the vector of -values I happened to witness – how do quadratic-loss-minimizers tend to vary? Here, we’ll focus on this latter question, mostly because it’s easier to answer, but also because it’s more relevant, given we saw the data we did.
Now, without knowing the distribution it’s hard to say much about the variation we should expect in our quadratic-loss-minimizing lines. But we can make the problem tractable by imposing some additional constraints.
For example, assume that, conditional on the vector of -values, each response is independent of every other response . Assume also that – again conditional on the vector of -values – the variance of the responses is constant, and denote that constant variance by ‘’. In other words, assume that for the vector of values, .
Given that assumption, we can compute the covariance matrix of as follows:
I think the generality of this result somewhat surprising, because it only relies on conditional independence and constant variance. Consider the below picture. It shows 20 100-data-point samples from a fixed-conditional-variance distribution, where , along with 20 corresponding quadratic-loss-minimizing lines:
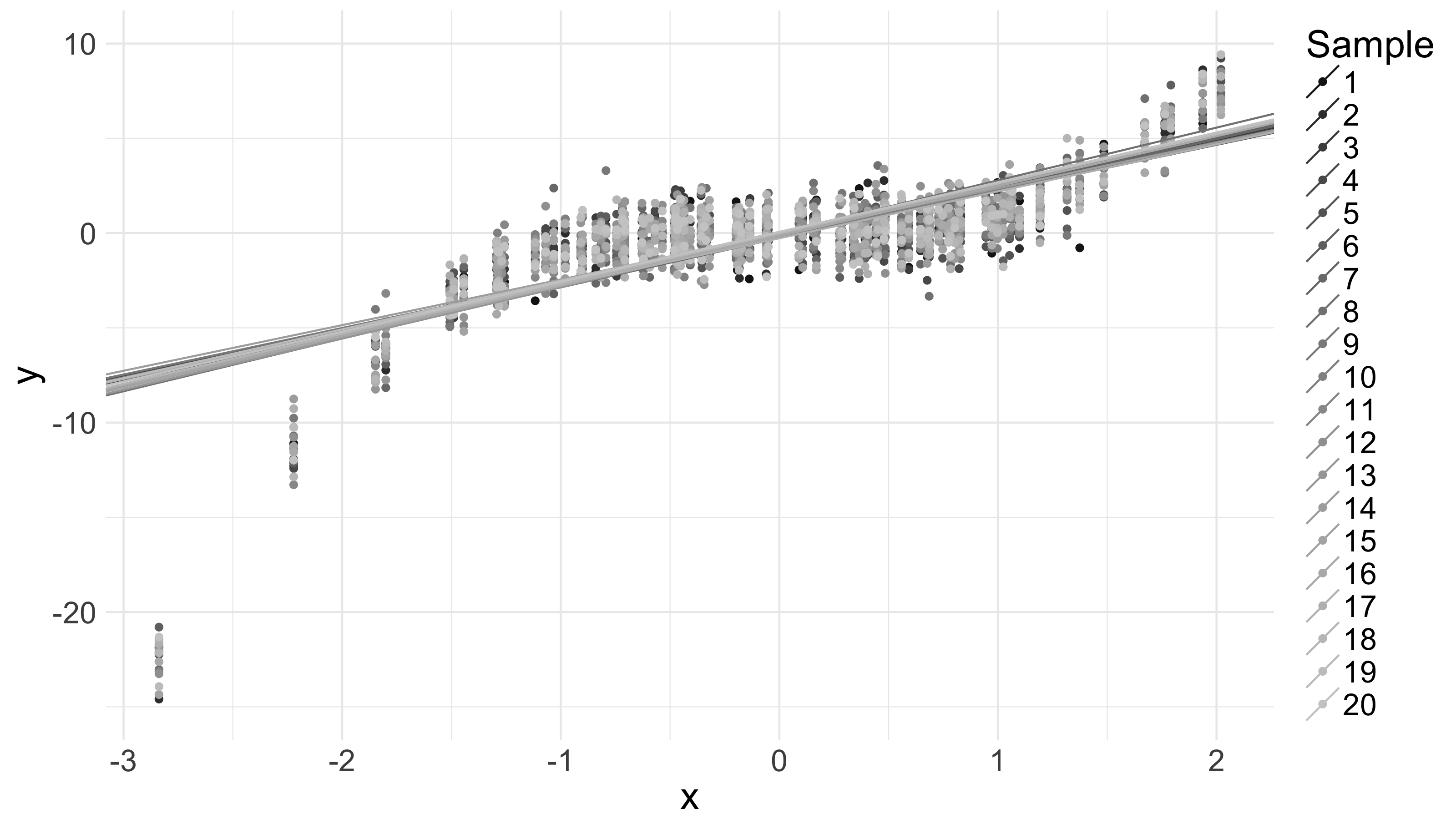
Now, compare that picture to a similar picture below – with the same -values, but where the -values are generated from a distribution with – i.e., where the conditional mean of is a linear, instead of a cubic, function of :
We see generally different slopes across the two plots. That’s not surprising. But consider: both plots are on the same scale, and the variation in the quadratic-loss-minimizing lines is (approximately) the same in both cases. This, despite the fact that the conditional mean of is a much more complicated function of in the former case than in the latter.
I think that last is surprising. More precisely, I think it surprising that the covariance matrix of – which expresses the amount of variation in our quadratic-loss-minimizing lines – is independent of considered as a function of . Under every such function the expected variation in our quadratic-loss-minimizing lines is the same.
That’s enough for now; something that is also surprising is that there is still more to say about drawing straight lines through a crop of data points. So, still more to come on this.
Code below: generate 20 100-data-point samples from the same conditional distribution, and plot quadratic-loss-minimizers for each.
require(ggplot2)
## Init structures to store samples
df <- NULL
beta_hat <- NULL
## Generate some x-values. X[,2] ~ N(0, 1)
X <- matrix(c(rep(1, 100), rnorm(100)), ncol = 2)
## Over 20 iterations, generate 100 y-values, Y ~ N(X[,2], 1),
## and compute quadratic-loss-minimizers
for (i in seq(1:20)){
Y <- rnorm(100, mean = X[,2])
df <- rbind.data.frame(df, cbind.data.frame(x = X[,2],
y = Y,
iter = i))
## Find (X'X)^(-1)X'Y.
bh <- solve(t(X) %*% X) %*% t(X) %*% Y
beta_hat <- rbind.data.frame(beta_hat,
cbind.data.frame(intercept = bh[1],
slope = bh[2],
iter = i))
}
## Plot the samples along with their quadratic-loss-minimizers.
ggplot(df, aes(x = x, y = y, color = as.factor(iter))) +
geom_point() +
theme_minimal() +
scale_color_grey(start = 0.1, name = 'Sample') +
theme(text = element_text(size = 20)) +
geom_abline(data = beta_hat,
aes(intercept = intercept, slope = slope, color = as.factor(iter)))